…for the DNA folks
Anyone who knows The Legal Genealogist knows that the term “utterly-math-averse” applies, in spades.
But the lesson we all have to learn, no matter how hard it is to wrap our heads around it, is that we need to play the odds when we’re looking at possible relationships based on how much DNA we share with a match.
And the Shared cM Project — now in its fourth iteration as the long-awaited version 4 was released this past week — offers up that lesson in math and statistics for all the DNA folks out there.
The project — begun in March of 2015 — is the brainchild of Blaine T. Bettinger, author of The Genetic Genealogist blog and a recognized expert on genetic genealogy.1 It’s a sterling example of citizen science in action, collecting and analyzing data to help us all understand the likelihood of a particular relationship with a DNA match based on the amount of DNA we share.
In the introduction to the PDF setting out the results of version 4 of the project, Blaine explains that the project is “a collaborative data collection and analysis project created to understand the ranges of shared centimorgans associated with various known relationships.”2
In other words, if you have a match with whom you share — say — 350 cM of DNA, just what are the chances that your relationship to that match is that of parent-child (answer: zero) or first cousin once removed (answer: better than 50%)?
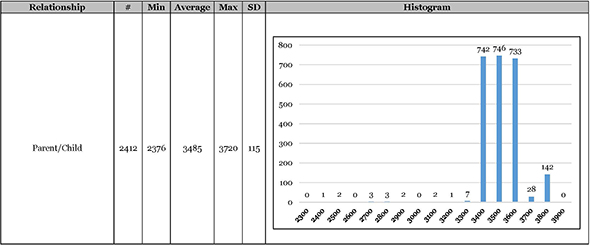
There are of course charts showing the percentage we might expect,3 but how much better would we understand those chances if the information we had was based on actual experience?
That’s what Blaine set out to do — first with more than 6,000 data samples in version 1 (May 2015), then more than 10,000 in version 2 (June 2016), then more than 25,000 in version 3 (August 2017) and, now, nearly 60,000 data samples in this new version 4.4
As a result, we all know a lot more than simply that we can expect to share as much as 12.5% (850cM) of our DNA with a first cousin. We know that, in real life, people have reported sharing as little as 500cM and as much as 1400cM — but those are real outliers. The vast majority of first cousins share between 800-1100cM with the biggest spike in the histogram5 around 900cM.
As the number of submissions has grown, there have been changes in the project’s results. Set out on page 2 of the downloadable PDF setting out the results is a list of key changes from version 3, including the addition of another 32,999 data points, a new methods section, a change in terminology from “Clusters” to “Groupings” to avoid confusion with shared match clusters, and lots and lots of new histograms — charts showing visually the results most often reported for known relationships.6 And on page 55 comes a chart showing the changes in reported results between version 3 and version 4.7
What makes this lesson in numbers even better is that these new results are now fully incorporated into the shared cM tool at DNA Painter — including a new feature to see the histogram for any particular relationship suggested by the tool.8 So we can now enter that 350cM we share with a new match, see the relationship probabilities for various relationships as before — but go on now to click on, say, 2C (second cousin), and see the actual histogram for that relationship — then compare it to the histogram for, say, 2C1R (second cousin once removed). It’s really easy then to see just how much more likely it is that the match is a second cousin than a second cousin once removed.
The amount of work required to collect and analyze this data is staggering. Its value is enormous, and we all owe Blaine and the DNA Painter folks a tremendous debt of gratitude for the effort put in to make it available to us in forms we can use.
It’s a lesson in numbers we all need.
Cite/link to this post: Judy G. Russell, “A lesson in numbers,” The Legal Genealogist (https://www.legalgenealogist.com/blog : posted 29 Mar 2020).
SOURCES
- See Blaine T. Bettinger, The Genetic Genealogist (https://thegeneticgenealogist.com/ : accessed 29 Mar 2020). See also Blaine T. Bettinger, The Family Tree Guide to DNA Testing and Genetic Genealogy, 2d edition (Cincinnati: Family Tree Books, 2019), and, with Debbie Parker Wayne, Genetic Genealogy in Practice (Arlington, Va. : National Genealogical Society 2016). ↩
- Blaine T. Bettinger, The Shared cM Project
Version 4.0 (March 2020), PDF at page 1. ↩ - See e.g. ISOGG Wiki (https://www.isogg.org/wiki), “Autosomal DNA statistics,” rev. 3 Sep 2018. ↩
- See Bettinger, The Shared cM Project
Version 4.0 (March 2020), PDF at page 4. ↩ - A histogram by definition is “a diagram consisting of rectangles whose area is proportional to the frequency of a variable and whose width is equal to the class interval.” Lexico, powered by Oxford (https://www.lexico.com/ : accessed 29 Mar 2020), “histogram.” I warned you: there’s math in this stuff! ↩
- See Bettinger, The Shared cM Project
Version 4.0 (March 2020), PDF at page 2. ↩ - Ibid., PDF at page 55. ↩
- See Jonny Perl, “Introducing the updated shared cM tool,” DNA Painter Blog, posted 27 Mar 2020 (https://dnapainter.com/blog/ : accessed 29 Mar 2020). ↩


The addition of histograms from the cM probability page is a great, great enhancement! Thank you Jonny Pearl for developing DNAPainter and continuing to provide amazing enhancements, and to Blaine Bettinger for the Shared cM Project and all the data!