Yes, The Legal Genealogist is aware of the upcoming change at AncestryDNA to eliminate the smallest of our small-segment matches.
Yes, I’m aware this will mean potentially thousands of matches not showing up any more.
And I have some advice about this:
Chill.
Let me repeat that.
Chill.

So… the announcement from AncestryDNA explains that “Our updated matching algorithm will increase the likelihood you are actually related to your very distant matches. As a result, you’ll no longer see matches (or be matched to people) that share less than 8 cM with you – unless you have added a note about them, added them to a custom group or have messaged them. These changes to the matching algorithm will reduce the total number of DNA matches you have and the number of new matches you will receive. It may also affect the number of ThruLines you may see.”1
And the genetic genealogy community went into a tizzy bemoaning all the lost data and lost research opportunities and how could Ancestry do this and they’re only out for the money.
Sigh.
Let me say it again.
Chill.
Seriously.
Chill.
First off, you can save any that you for some reason think are really essential.
Second, few if any of these are really essential.
Let’s start with the “you can save any” part. If you really think you need this information, pop over to Roberta Estes’ DNAeXplained blog and follow her excellent guidance in the post “Ancestry to Remove DNA Matches Soon – Preservation Strategies with Detailed Instructions.”2
In short, these get saved if you’ve ever added a note about one of these matches, added them to a group (including adding a star), or sent them a message. And you can do that now if for some reason you think they’re really essential..
But let’s consider the second part: few if any of these are really essential.
After all, if in all the time you’ve had these matches, you haven’t added a note, added them to a group or sent them a message, just how important are these matches?
The truth is, for the vast majority of researchers — the very serious professional geneticists excepted — they’re not important at all.
First, a huge percentage of these small segment matches are false positives. Those that aren’t tend to be so far back in time that the average researcher will never be able to discover which of our many many ancestors might have been the source of that segment. The best discussion of this aspect of this change is in Blaine Bettinger’s post, “Losing Distant Matches at AncestryDNA.”3
Second, even if the match is a real one — not a false positive — the odds are it’s to someone who’s going to end up being about a sixth cousin.4
So… my sixth cousins and I share a set of fifth great grandparents. We all have 128 fifth great grandparents. So… how many have we actually identified so we might possibly begin to figure out how a match matches us?
For me, looking at my tree completeness report at DNAPainter.com, it’s pretty depressing:
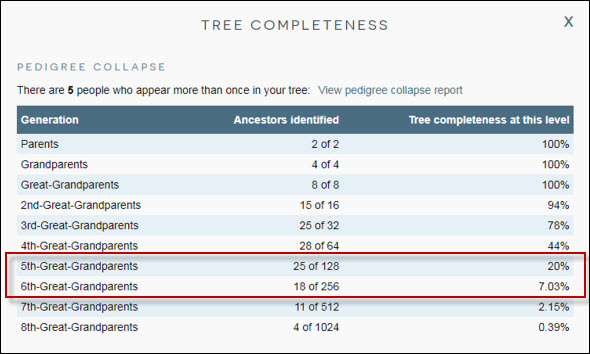
It’s 25 out of those 128 people. Just 20%. At the sixth great grandparent level, I’ve only identified 18 of 256 — just seven percent.
Some of that is because of a brick wall at one of my maternal second great grandfathers. Some of it is because of an illegitimacy in 1855 Germany. Neither of those is likely to be solved with tiny DNA matches of questionable origin who may not be real matches at all.
In part, it’s because there are just too many people in my match list to begin to manage or cope with. I checked this morning to see just about many matches I have at the level of the smallest segment Ancestry is going to eliminate — the 6cM level.5
It took me 20 minutes to scroll to the bottom of my list of 6cM matches. Turns out I have 13,989. Of those, 3,402 have no trees at all. Another 3,441 don’t have their DNA linked to a tree.
I can’t work with 13,989 matches who may not be real matches at all. I can’t begin to work with the 6,000+ who don’t even have a tree linked to their DNA.
Now I can hear the splutters already. But what about those who do have a tree and do have an ancestor in their tree in common to mine?
Of 13,989 matches at the 6cM level, only 122 have someone in their tree who’s also in my tree.
How many of these have I messaged because of the DNA match? None.
How many of these have ever messaged me? None.
And — most important — of all those who share a common ancestor with me, how many could I have found simply by following a tree hint? All of them.
So… what does it add to my proof that a tree hint comes from someone who matches my DNA at the 6cM level? Just about nothing until and unless I can show that the DNA couldn’t have come from some other proposed common ancestor. And until my tree completeness is a whole lot better than 7-20% — and unless my match’s tree completeness is a whole lot better as well — I can’t show that.
And let’s look at another metric here. Just as we know that there are an awful lot of false positives at the 6-7cM level, where we’re going to lose these reported matches, we know that the vast majority of matches above 20cM are for real. And it’s at that 20cM level that Ancestry reports shared matches (you only see the shared matches who might be fourth cousins or closer, and Ancestry defines that at the 20cM level).
So I took a look at the number of matches I have at AncestryDNA with whom I share 20cM or more of DNA. As of today, there are 3,072 of them. How long is it going to take me to seriously work with 3,000+ matches — any one of whom offers a much much better chance of actually discovering something genealogically useful than any of those 6cM matches?
Just looking at those with whom I share the smallest amount in that group — those with whom I share exactly 20cM — I have 530 matches. Take out the ones with no tree at all and I have 387 to work with.
How long is it going to take me to seriously work with 387 potential matches?
I have enough to work with. I’m literally drowning in data I can’t even get to. This is the case for the vast majority of us — with just maybe the very serious professional geneticist-researchers excepted.
Losing these very small probably-false matches is No Big Deal.
This is why our response to this Ancestry announcement should be very simple.
Chill.
Cite/link to this post: Judy G. Russell, “Chilling with AncestryDNA,” The Legal Genealogist (https://www.legalgenealogist.com/blog : posted 19 July 2020).
SOURCES
- “Updates coming soon to DNA matches,” announcement header on DNA match lists, Ancestry.com (https://www.ancestry.com : accessed 19 July 2020). ↩
- Roberta Estes, “Ancestry to Remove DNA Matches Soon – Preservation Strategies with Detailed Instructions,” DNAeXplained, posted 16 July 2020 (https://dna-explained.com/ : accessed 19 July 2020). ↩
- Blaine T. Bettinger, “Losing Distant Matches at AncestryDNA,” The Genetic Genealogist, posted 17 July 2020 (https://thegeneticgenealogist.com/ : accessed 19 July 2020). ↩
- You can check this. Head over to DNAPainter.com, click on Tools, choose The Shared cM Project 4.0 tool v4, and enter 6 and then 7 in the filter box. You’ll see that the odds are really high that you’re looking at a sixth or more distant cousin. ↩
- cM remember is the abbreviation for centimorgan, a unit of measuring how closely two DNA matches are related. The bigger the number, the more closely related. See ISOGG Wiki (https://www.isogg.org/wiki), “centiMorgan,” rev. 2 Jan 2019. ↩


In an era when no one seems capable of it, sound advice.
This is an unrelated question / comment. Unfortunately I have a condition that to continue living, I need a bone marrow transplant. Prior to this happening (it is scheduled soon) is there any suggestions that you have regarding my current DNA?
Thank you for your response.
Not being a medical expert, I’m not sure there’s anything I could say that would be helpful.
I have matched 8th cousins and wish to push this technology to its theoretical limits. Ancestry is now even less useful than it used to be.
I’m sorry your thousands and thousands of real matches aren’t useful. (I mean, seriously)
We now have programs that can process 1000 triangulations in 20 runs. I have autosomal data work back to 1740s. Seriously I will push this tech to its theoretical limits of 9th to 10th cousin range.
When you can show me that these are all phased (not possible for most people) and reliable (not possible for anybody yet), I’ll be delighted. We all hope the science (not the wishful thinking and not the confirmation bias circular reasoning) will move the goalposts. In the meantime, the thousands and thousands of remaining matches are plenty for everyone else.
I think we are going to need a bigger computer 🙂
Ain’t that the truth… And more computational power than any system has yet!!
This might be a dumb question, but… When you talk about shared centimorgans, do you mean the longest block shared with some one, or the total number of centimorgans in general?
It’s both, really. Any individual segment that’s that small poses the high risk of being false, so adding up a bunch of 1cM segments to come up to 8-10cM doesn’t make that match any more likely. And any match where you share only a small amount of DNA overall poses the risk of a false positive.
Chilling and raising a glass of iced tea in a toast for another down to earth explanation… Thanks Judy
Nicely put, Judy! I do wish Ancestry would lower the 20 cM threshold for Shared Matches to 15 cM, though!
Agreed on the shared matches — and maybe if this frees up some computational power, it’ll be doable.
When I filtered for 6-7 cM, with trees and a common ancestor I had a lot of matches that gave me solid clues to purse in my research. It also took me past the generations that I had entered on my own tree. Seeing a common ancestor such as Abraham Jones attached to DNA match’s tree is more helpful than just searching for any Jones surname on any tree in Ancestry. So for me the 6-7 cM have provided me with leads. And I know I need to be cautious with information on public trees but it is still a place to start.
Thank you for the detailed, calm and rational explanation.
The really great thing about the upcoming changes is displaying the length of your longest segment. This will be tremendously useful for those of us in Jewish or other endogamous populations. Plus I’ve been wanting them to get rid of these tiny matches ever since I tested. This is wonderful news and I can’t wait until they roll this out!
Thanks for the reasonable explanation. I admit my first reaction to the news was apprehensive, but agree with that you have set out here.
I’ll try to chill. But I agree with Doug. I have several matches at the 6-7 cM level that, in turn, have several shared matches at a higher cM level with trees and attached sources going back to the common ancestor. In many cases this goes back to a 5th g-grandparent or higher reaching into the 1700s. These are early American ancestors – granted, this is a lot harder to do with more recent immigrant ancestors. If this isn’t firm proof, to me, it’s at least anecdotal evidence that some of these lower matches have validity. Yes, I have notes and have assigned them to groups – precisely because I’ve discovered them. I won’t be able to with this change. I agree that individually, we can’t process every one of these matches that comes our way. But in the broader scheme of things, I think Ancestry is reducing our collective ability to discover these kinds of matches that could help us work through brick walls.
If this happens, I am not worried. I have enough problems getting matches at the 3rd and 4th cousin level to e-mail me back. No one does-a simple courteous message back would be wonderful. Geez-I am a 73 year old woman who just wants to solve some brick walls. And, most matches have no trees to work off of. I do use “shared matches” to point me in the direction of where we might match up-father or mother’s side.
Must be nice to be drowning in DNA matches that you don’t care to lose thousands more matches than some of us have.
Dreaming of one day having 13,000 matches to lose. No I’m not talking 4th cousins as of this week there’s 15 of them. But I’ll be chilling patiently for a 30 cm match. Maybe there will be one in the next 18 million who test.
I also hear there’s false compiled genealogies as well. Looking forward to ancestry deleting all original unsourced ones created before 1900. You know some genealogists can’t be trusted understand that a percentage of these are fake and they need to look for corroborating evidence. But chill you don’t have enough time to read them all and the photocopies you have now you can keep.
No testing company can provide unlimited computational power to support vast numbers of false positive matches on the off chance that a handful will prove valuable for somebody. We’re just going to have to accept that.
Oh my GOODNESS thank you!! Those distant matches (less than 10cM shared) are a needless bloat and when they are “highlighted” by Ancestry because the user included a photo (but no tree!) it’s maddening.
Even on my partner’s tree, who has a few lines going back to the 18th century, we can’t make corroborated connections on those distant matches.
I welcome the changes.
On one hand, I completely agree with you.
On the other, I must note that one 7cM match opened the door to an ancestor’s brothers’ line that went to the USA and had thousands of descendants – about as big as our branch in Australia.
Still, now Ancestry should have more space on its servers – plenty enough to extend Shared Matches down from 20cM to 15cM – don’t you think?
Yes, those tiny matches are hard and frustrating, but that is what requires me to take out an Ancestry subscription to puzzle them out.
Without those tiny matches I have way less reason to give them money.
At the end of the day this isn’t about Ancestry making things more accurate, it’s about Ancestry saving money and improving their profits. That is what bothers me the most about the change. That they aren’t be honest why they make they’re making change is disappointing.
I still would have like a download to excel function like 23andme, MyHeritage and FTDNA offers. Please, Ancestry?
Wouldn’t that be nice…
Judy, you’ve made the case for the “average researcher”. Bravo. Now for the rest of us (those serious genealogists who do indeed depend on small distant DNA matches for their research) this is a serious blow. No, we will not “chill”.
Read and sign the petition if you too are against Ancestry taking away your small matches:
https://www.ipetitions.com/petition/ancestry-dont-delete-our-dna-matches
And read the comments for some perspective from those who do depend on these matches.
I’m not opposed to this move. I think it’s a good move. At a minimum we need to trash the false positives, and there are a bunch of those.
Thank you to all who posted in defense of the usefulness of many of those smaller segments… some of them can and do, especially in groupings, serve up extremely useful ‘hints’, at the least to brick walls or ancestors shared beyond the 3rd or 4th cousin range. Many of us have tested and pay for precisely that — to fish (yes, very carefully and selectively) in the huge Ancestry DNA database for matches for leads on our 4-6th or 7th great-grandparents.
Perhaps these trees are more developed than the ‘average’ Ancestry user’s mentioned and go only several generations back… BUT since when did average and majority become the standard — when did more serious genealogy become not worth supporting, by ripping away the precise cM range which may (and actually does) provide some useful leads. I find it discouraging, the dismissive, even a bit sarcastic, tone given toward those who are serious researchers working very hard to use these tools to make potentially valid breakthroughs, and do, where otherwise have failed. Some of these breakthrough trees may well be the ones being copied later, some only because of 6-7 cM shared matches… Look carefully at the relationships chart for this amount! Is AncestryDNA only for people with relatively shallow trees? With this attitude we may lose many of the best, deepest trees as people working in that range quit Ancestry.
Ancestry, please give the serious researchers, or those who need or want it, the option/setting to use our “smaller cM matches” (matches, kept in ThruLines, etc.).
For the rest who don’t care, maybe make the 8 cM (or the amount they choose) threshold a default…. if you really need to.
And, please, fellow genealogists, don’t demean, or talk down to those of us who have found real value in them — NOT found in a larger match or elsewhere. We can chill, but that doesn’t mean that it’s okay to take these away. Maybe you don’t need them or don’t care, but others are in a different situation genealogically and do.
Thanks for ‘listening’.
People who think small segments at Ancestry (with the company’s own admission that at least 50% are false positives, and with no chromosome browser, no ability to triangulate even assuming there was a shred of evidence that triangulation works for these segments and not even the ability to cluster) are a “serious” researcher’s tool are fooling themselves.
Thanks for the heads up, Judy. For the last three days, I have been saving my 6 cM and 7 cM matches in a group or sent them a note. I am hoping that will save them in my ThruLines. These are people that I can prove thru marriage and census records that belong in my ancestry. Without ThruLines, I would have never found them. Now I can CHILL.
You have also overlooked all of us non-serious genealogists who have happened to discover their adoption, and have adoptive parents who have passed or are uncooperative, and suffer from the dead-ends of obtaining birth records.
I’m compelled to re-post what I said in Blaine’s FB group:
“There are 2 ways to view this, imo. The 1st is looking at the validity of low cM matches from a technical (valid familial DNA) standpoint, and in those cases they are probably no huge loss on the balance.
The second however is genealogical & the loss of those matches with whom you share a Common Ancestor or surname match clue. In those cases it could be/is a huge loss. As an adoptee I view it the second way. Clues were/are vital to me.
I have (only because I tagged them pre-purge) 109 6 to 7 cM matches with Common tree Ancestors, and 2005 with surnames that match direct paternal or maternal lines (as I know them).”
Let me repeat this: Clues were/are vital to me.
And as a 15+ year subcrriber there is no good reason imo that for the amount of ongoing subscription costs, that Ancestry couldn’t at least process and keep only these low cM matches which share a Common tree Ancestor.