Looking at the cousin match changes
Three weeks ago, Family Tree DNA began rolling out a number of changes, many of which greatly impacted its cousin-matching algorithm for its autosomal Family Finder test.
It took a bit longer than the company expected, as glitches began to surface.1 Soon after the rollout began, a notice appeared that the conversion would be complete this past week.
That time has now passed and — since The Legal Genealogist‘s match list has been stable for a few days — it appears to be the case that the matching part of the change is complete.2
With that in mind, I’ve reviewed what happened to my own matches.
I can tell you what happened.
In some cases, I haven’t got a clue as to why it happened. A White Paper is expected soon that may help, but for the moment, well, let me just say some of these have me stumped.
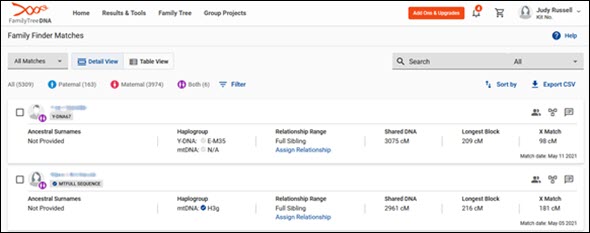
Here’s the overview of my changes:
I had 5564 matches before the change. As of yesterday, I had lost 1677 of them, with shared DNA ranging from 75 cM down to 19 cM and with longest shared blocks ranging from 22 cM down to 8 cM.
In total cM, I lost seven in the 70+ cM range, and 20 in the 60-69 cM range. Those may seem like very significant matches — but the vast majority of these were matches who reached those high shared numbers only by adding up lots and lots of very small (and potentially false) segments. Of those, only five had a longest shared block of 10 cM or larger — two at 10 cM, one at 11 cM, one at 14 cM and one at 22 cM.
The vast majority of those deleted from my match list were projected to be fourth or fifth to remote cousins where the largest shared chunk of DNA was so small as to pose a very real danger of being a false match.
Of all the ones I lost, I would like to see the White Paper explanation on only two: previously suggested second to fourth cousins with longest blocks at 20 cM or more.
In short, for me and for most researchers, losing the ones lost won’t be a critical loss.3 For most of us, these matches were — for the most part — either false positives or so far back in time that any hope of reliably identifying a common ancestor is utterly unrealistic.
On the plus side, I gained 1412 matches, with total shared DNA ranging from a high of 39 cM to a low of 8 cM, and longest blocks ranging from a high of 29 cM to a low of 7 cM (all of the 7 cM long block matches had total cM between 13-15 cM).
Two of those added are estimated to be in the 2nd-4th cousin range, and 99 in the 3rd-5th cousin range. The vast majority of the rest were fourth to remote. The old fifth to remote cousin range appears to have been eliminated.
Just about every match that carried over changed in some way. One brother went from 2858 cM total shared DNA to 3075 cM shared and 184 cM longest block to 209 cM. Another went from 2566 cM shared to 2760 cM shared and from 252 cM longest block to 274 cM. True first cousins went up in both total shared DNA and longest block, as did first cousins once removed. Most matches beyond the 1st-2nd cousin level dropped, often dramatically, in total shared DNA but often went up in longest block, sometimes dramatically.
Relationships are generally predicted to be closer than they were. Before, I had two predicted first cousins, two predicted 1st-2nd cousins, one predicted 1st-3rd cousin, and four predicted 2nd-3rd cousins — a total of nine. Now I have two predicted first cousins, two predicted 1st-2nd cousins, seven predicted 1st-3rd cousins and three predicted 2nd-3rd cousins — a total of 14.
And, before, I could easily tell you my relationship to every match in the ranges down to predicted 2nd-3rd cousins. Now there are six I need to work on, including — sigh — one with the very useful name of TBD TBD (to be decided).
Some of the changes in predicted relationship are very useful. Instead of simply predicting that someone sharing roughly 500 cM could be a 1st-2d cousin, the system now suggests that person might be a 1st Cousin – 2nd Cousin, Great/Half Uncle/Aunt/Niece/Nephew, Great Grandparent/Grandchild.
Others are utterly baffling. I am at a loss to understand how one match can be a predicted 1st-3d cousin sharing a total of 50 cM of DNA in one single long block but another can be a predicted 2nd-3rd cousin sharing 197 cM of DNA including a longest block of 72 cM and yet another can be a predicted 2nd-4th cousin sharing 118 cM of DNA including a longest block of 55 cM.
So that’s what happened to my matches.
Why some of it happened, well, maybe the White Paper will have an answer.
Some lost, and some found, in the changes at FTDNA.
Cite/link to this post: Judy G. Russell, “Lost and found at FTDNA,” The Legal Genealogist (https://www.legalgenealogist.com/blog : posted 25 July 2021).
SOURCES
- See Judy G. Russell, “Time for FTDNA’s change,” The Legal Genealogist, posted 4 July 2021 (https://www.legalgenealogist.com/blog : accessed 25 July 2021). ↩
- Some other changes, like speeding up the loading of match lists and fixing the match dates to reflect when they actually occurred rather than everyone being dated as a new 2021 match, are taking longer. Getting the matches right was the much higher priority. ↩
- Yes, I know this isn’t true for everyone. Some people were doing deep data mining on these small matches and I agree with them that advance notice of the change to allow them to capture the pre-existing data would have been A Good Thing. ↩


Nice discussion. And here I thought it was all cut & dried.
FWIW, I’m waiting for the original match dates to be restored before doing my final analysis.
That will be a bit easier, but boy does it take a lot of massaging to make the spreadsheet fields work for finding the carry-overs. One version has titles like Mr., the other doesn’t. One uses II, III, IV, the other doesn’t. Total pain…
I have a 1st to 3rd cousin predicted with one 50 cM segment. Definitely not a 1st cousin A quick and dirty tree for her leads me to think that’s she’s no closer than 4th cousin with a fluke long segment.
Yeah, I’m waiting to see how the White Paper explains this… I have my reservations…
I’d like to see you include an “hours worked” as part of your posts so people can begin to appreciate how much time it takes to do this work!
🙂 I’m not sure people really want to know…
Well, don’t complain. At least you have some matches to be puzzled about. My matches ALL disappeared after the “upgrade”, despite having an uncle and a number of cousins that surely would have survived even a faulty “upgrade”. Two reports to FTDNA have not returned a response beyond “wait until ______” and see if it is fixed. I’m sure someday all will be revealed, but it’s a good thing that I do 99.99% of my work with Y DNA, which mercifully seems to have survived the “upgrade” with the data intact.